
To Gather Data Is Human
We like to think we are data-driven. From large-scale government or business operations to individuals managing their budget, people justify decisions based on data. Our devices gather data to enable entities to aggregate vast amounts of data which are processed, analyzed, and correlated in order to draw conclusions. Data science (DS), machine learning (ML), and artificial intelligence (AI) all process large amounts of data to make decisions. SlashData has recently published its annual State of the Developer Nation Survey, which includes a section devoted to developers of machine learning applications and the type of data they use.
Defining Data
In this survey, data is defined according to two types: structured tabular data, and unstructured data, both of which can consist of images, video, audio and text. Structured tabular data is organized into rows and columns, and the unstructured data is, well, unstructured.
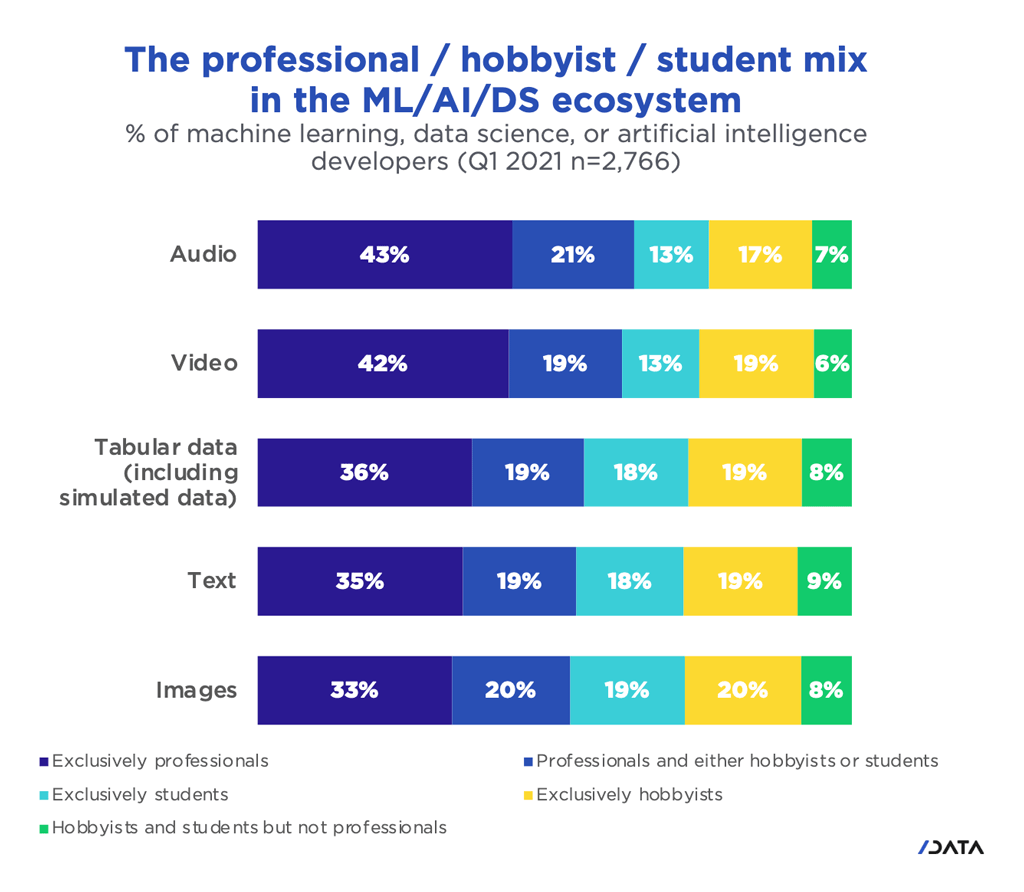
The survey further defines the types of developers using the data as either professionals or students/hobbyists, although the people in either category can belong to both (Table 1). While either category will use any type of data, 72% of students and 68% of professionals are focused on image classification; 38% of students and 32% of professionals are focused on natural language processing. Key applications in the visual category involve augmented and virtual reality development in games, medical imaging, and facial recognition for intelligence and security applications.
Table 1. The professional/hobbyist/student mix in the ML/AI/DS ecosystem.
Source: SlashData™.
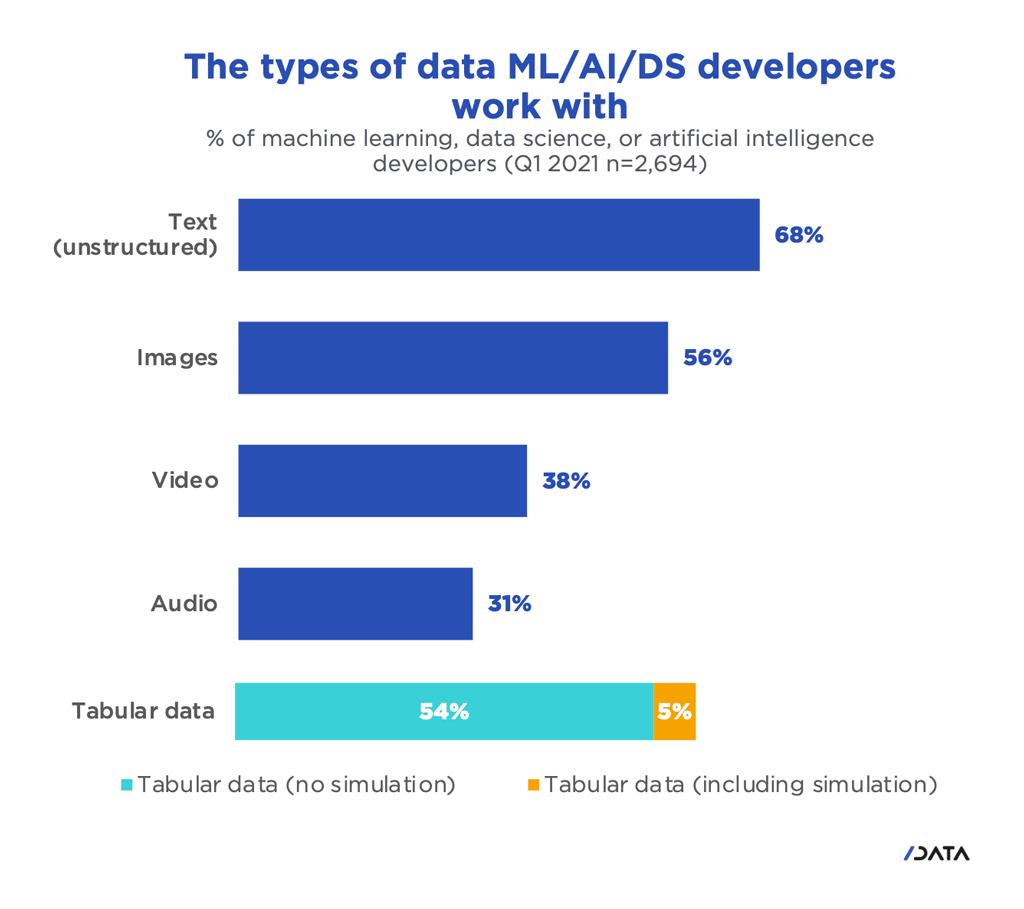
Unstructured text data is the most popular data among ML developers, and tabular data is a close second (Table 2). The most popular uses for tabular data are workforce planning and resource allocation. With all of the upheaval in global supply chains due to the COVID-19 pandemic, more effective planning tools will depend on AI and ML to smooth out inconsistencies in supply and demand.
The survey also found that audio data was most often combined with images or video or text to enhance the data provided by these formats. Many professionals rely on more than one data format in their projects.
Table 2. The types of data ML/AI/DS developers work with.
Source: SlashData™
Size Matters
“Big Data” has been a buzzphrase for a few years now, but the SlashData survey found that developers in the ML realm are often not using extremely large datasets. Tabular data, as expressed in the number of rows, is typically in the range of 1,000 to 20,000 rows for up to 25% of those developers surveyed. Depending on the application, this can stretch to 22% of developers working in the realm of 20,000 – 50,000 rows of data, and 21% working with 50,000+ rows of data.
The amount of data under analysis has several implications related to the size of the enterprise. Simply put, an enterprise engaged in Big Data analysis has to be adequately resourced with infrastructure to generate, store, process and analyze the datasets. For non-tabular data, the survey found that 18% of those surveyed used image datasets typically 50-500MB in file size, while only 8% were larger than 1TB in size.
Another consideration associated with datasets or file size is the processing power and hardware required to manipulate the data. The survey found that, depending on the file sizes associated with the datasets, 26% of the developers using text data and 41% of those using video data would require specialized hardware to handle their data, limiting the development opportunities as the size of Big Data increased.
What to Say to Developers
The SlashData survey provides several insights around machine learning developers and the data they use. Unstructured data is most prevalent in machine learning applications, and most of the work being done in this area is completed by professionals as opposed to students or hobbyists, even though ML, AI, and DS are some of the hottest fields in software development — particularly given the growth of cybercrime and the need for cybersecurity. Today, in its present state, the data they are using does not necessarily involve big datasets due to the associated resources needed to process the data. Keep this in mind when providing resources to developers.
Resources
- SlashData: https://www.slashdata.co/
- SlashData: State of the Developer Nation report


